- 商品
- 详情
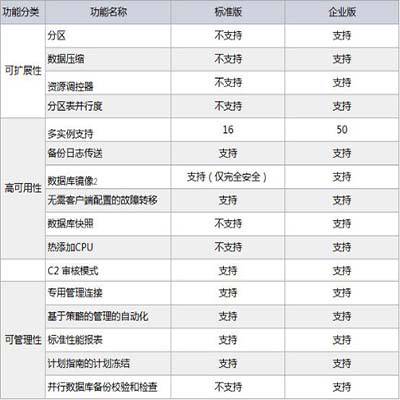
- 数据库产品特性
- 微软品牌
- SQL SERVER型号

部署生产就绪脚本使用 T-SQL 和存储的过程
传统上,数据科学解决方案的集成目的是用于支持性能和集成大量重新编码。 SQL Server 机器学习服务可简化此任务,因为可以在 SQL Server 中运行 R 和 Python 代码,并使用存储的过程调用。 有关存储过程中嵌入代码的技巧的详细信息,请参阅:
快速入门:SQL Server 中的"hello world"R 脚本
sp_execute_external_script
通过使用存储的过程将 R 代码部署到生产环境的更完整示例,请参阅教程:SQL 开发人员的 R 数据分析
针对 SQl 优化 R 代码的准则
转换 R 代码在 SQL 中的是 R 或 Python 代码中事先完成某些优化,更容易。 其中包括避免会导致问题的数据类型、 避免不必要的数据转换和重写为可以轻松地参数化的单个函数调用的 R 代码。 有关详细信息,请参阅:
R 库和数据类
转换 R 代码以便在 R Services 中使用
使用 sqlrutils helper 函数
与应用程序中集成 R 和 Python
因为你可以从存储过程中运行 R 或 Python,可以从任何应用程序可发送 T-SQL 语句和处理结果来执行脚本。 例如,你可能会重新训练模型按计划通过使用执行 T-SQL 任务在 Integration Services,或通过使用另一个作业计划程序可以运行存储的过程。
评分是一项重要任务,可以轻松地自动执行,或从外部应用程序启动。 训练模型事先使用 R 或 Python 或存储的过程,并以二进制格式保存模型到表。 然后,可以将模型加载到一个变量,作为存储的过程调用,以获得评分从 T-SQL 使用这些选项之一的一部分:
实时针对小批量评分,优化
单行计分,来从应用程序的调用
本机计分,用于从 SQL Server 而不会调用 R 的快速批预测
本演练提供评分使用批处理和单行模式中的存储的过程的示例:
端到端数据科学演练的 SQL Server 中的 R
请参阅有关如何将集成的应用程序中评分的示例这些解决方案模板:
零售预测
欺诈检测
聚类分析的客户

 在线问
在线问
- 数据库
- 微软
- SQL SERVER
- SQL SERVER
- 2000
- 编程开发软件
- 全国联保
- 1用户
- windows 2008
- 提供发票
- 光盘+正版标签
- 序列号/CDK
